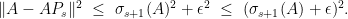1. Low-rank approximation of matrices
Let 
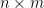
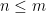



It is known that a truncated singular value decomposition gives an optimal solution to this problem. Formally, let 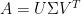


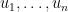



Fact 1
is a solution to
, and the minimum value equals
.
Another way of stating this same fact is as follows.
Fact 2 Let
be the
matrix consisting of the top
be the orthogonal projection onto the span of
. Then
is a solution to
.
The SVD can be computed in 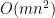

In the past 15 years there has been a lot of work on sophisticated algorithms to quickly compute low-rank approximations. For example, one could measure the approximate error in different norms, sample more or fewer vectors, improve the running time, reduce the number of passes over the data, improve numerical stability, etc. Much more information can be found in the survey of Mahoney, the review article of Halko-Martinsson-Tropp, the PhD thesis of Boutsidis, etc.
2. Rudelson & Vershynin’s Algorithm
Let 

The stable rank (or numerical rank) of

Clearly the stable rank cannot exceed the usual rank, which is the number of strictly positive singular values. The stable rank is a useful surrogate for the rank because it is largely unaffected by tiny singular values.
Our theorem will be invariant under scaling of 
Let 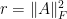
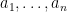
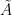
- Initially
- Fix any
. (Here we are assuming that the algorithm knows
, or at least reasonable bounds on
- For
- Pick a row
with probability proportional to
.
- Add the row
to
- Pick a row
- Compute the SVD of
, this takes
time.
Theorem 3 Fix any
. Let
be the orthogonal projection onto top
,
In other words, the best rank
Corollary 4 Set
. Let
Let us contrast the error guarantee of (1) with the guarantee we achieved in the previous lecture. Last time we sampled a matrix by sampled a matrix
and showed it approximates
in the sense that
We say that our result from last time achieves “multiplicative” or “relative” error guarantee. In contrast, Corollary 4 only guarantees that
even though
may be significantly smaller than
. We say that today’s theorem only achieves “additive” or “absolute” error guarantee. To prove today’s theorem, we will use a version of the Ahlswede-Winter inequality that provides an additive error guarantee.
Theorem 5 Let
be a random, symmetric, positive semi-definite
matrix such that
. Suppose
for some fixed scalar
. Let
be independent copies of
, we have
The proof is almost identical to the proof of Theorem 1 in Lecture 13. The only difference is that the final sentence of that proof should be deleted.
Our Theorem 3 is actually weaker than Rudelson & Vershynin’s result. They show that one can take
to be roughly
, which is quite remarkable because it is “dimension free”: the number of samples does not depend on the dimension
. Unfortunately our proof, which uses little more than the Ahlswede-Winter inequality, does not give that stronger bound because the failure probability in the Ahlswede-Winter inequality depends on the dimension. Rudelson & Vershynin prove an (additive error) variant of Ahlswede-Winter which avoids avoids this dependence on the dimension. Oliveira 2010 and Hsu-Kakade-Zhang 2011 give further progress in this direction.
2.1. Proofs
The proof of Theorem 3 follows quite straightforwardly from Theorem 5 and the following lemma, which we prove later.
Lemma 6 Let
Proof: (of Theorem 3.) We defined
Let
be independent, identically distributed random matrices with the following distribution:
This is indeed a probability distribution because
Note that the change to
during the
th iteration of the algorithm is
.
We will apply Theorem 5 to
. We have
so
. We may take
, the stable rank of
Since
and
, we get
by Theorem 5.
Now we apply Lemma 6 to
Taking square roots completes the proof.
Proof: (of Corollary 4). By the ordering of the singular values,
implying
. In particular, if
then
.
Proof: (of Lemma 6). Let
be the orthogonal projection onto the kernel of
left singular vectors of
So,
where the last step uses the following fact.
Fact 7 Let
and
and
respectively denote the
th largest eigenvalues of
Proof: See Horn & Johnson, “Matrix Analysis”, page 370.





![\displaystyle {\mathrm{Pr}}\Bigg[~ \Big\lVert \frac{1}{k} \sum_{i=1}^k Y_i - {\mathrm E}[Y_i] \Big\rVert > \epsilon ~\Bigg] ~\leq~ 2n \cdot \exp( - k \epsilon^2 / 4R ).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathrm%7BPr%7D%7D%5CBigg%5B%7E+%5CBig%5ClVert+%5Cfrac%7B1%7D%7Bk%7D+%5Csum_%7Bi%3D1%7D%5Ek+Y_i+-+%7B%5Cmathrm+E%7D%5BY_i%5D+%5CBig%5CrVert+%3E+%5Cepsilon+%7E%5CBigg%5D+%7E%5Cleq%7E+2n+%5Ccdot+%5Cexp%28+-+k+%5Cepsilon%5E2+%2F+4R+%29.+&bg=ffffff&fg=000000&s=0&c=20201002)

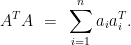
![\displaystyle {\mathrm{Pr}}\Bigg[~ Y_j ~=~ \lVert A \rVert_F^2 \cdot \frac{ a_i a_i ^T}{ a_i ^T a_i } ~\Bigg] ~=~ \frac{a_i ^T a_i}{ \lVert A \rVert_F^2 }.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathrm%7BPr%7D%7D%5CBigg%5B%7E+Y_j+%7E%3D%7E+%5ClVert+A+%5CrVert_F%5E2+%5Ccdot+%5Cfrac%7B+a_i+a_i+%5ET%7D%7B+a_i+%5ET+a_i+%7D+%7E%5CBigg%5D+%7E%3D%7E+%5Cfrac%7Ba_i+%5ET+a_i%7D%7B+%5ClVert+A+%5CrVert_F%5E2+%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle {\mathrm E}[ Y_j ] ~=~ \sum_{i=1}^n \frac{a_i ^T a_i}{ \lVert A \rVert_F^2 } \cdot \Bigg(\lVert A \rVert_F^2 \cdot \frac{ a_i a_i ^T}{ a_i ^T a_i } \Bigg) ~=~ \sum_{i=1}^n a_i a_i ^T ~=~ A ^T A,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathrm+E%7D%5B+Y_j+%5D+%7E%3D%7E+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac%7Ba_i+%5ET+a_i%7D%7B+%5ClVert+A+%5CrVert_F%5E2+%7D+%5Ccdot+%5CBigg%28%5ClVert+A+%5CrVert_F%5E2+%5Ccdot+%5Cfrac%7B+a_i+a_i+%5ET%7D%7B+a_i+%5ET+a_i+%7D+%5CBigg%29+%7E%3D%7E+%5Csum_%7Bi%3D1%7D%5En+a_i+a_i+%5ET+%7E%3D%7E+A+%5ET+A%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathrm{Pr}}\Bigg[~ \Big\lVert \tilde{A} ^T \tilde{A} - A ^T A \Big\rVert > \epsilon^2 / 2 ~\Bigg] ~=~ {\mathrm{Pr}}\Bigg[~ \Big\lVert \frac{1}{k} \sum_{j=1}^k Y_j - {\mathrm E}[ Y_j ] \Big\rVert > \epsilon^2 / 2 ~\Bigg] ~\leq~ 2n \cdot \exp( - k \epsilon^4 / 16r ) ~=~ 2/n,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathrm%7BPr%7D%7D%5CBigg%5B%7E+%5CBig%5ClVert+%5Ctilde%7BA%7D+%5ET+%5Ctilde%7BA%7D+-+A+%5ET+A+%5CBig%5CrVert+%3E+%5Cepsilon%5E2+%2F+2+%7E%5CBigg%5D+%7E%3D%7E+%7B%5Cmathrm%7BPr%7D%7D%5CBigg%5B%7E+%5CBig%5ClVert+%5Cfrac%7B1%7D%7Bk%7D+%5Csum_%7Bj%3D1%7D%5Ek+Y_j+-+%7B%5Cmathrm+E%7D%5B+Y_j+%5D+%5CBig%5CrVert+%3E+%5Cepsilon%5E2+%2F+2+%7E%5CBigg%5D+%7E%5Cleq%7E+2n+%5Ccdot+%5Cexp%28+-+k+%5Cepsilon%5E4+%2F+16r+%29+%7E%3D%7E+2%2Fn%2C+&bg=ffffff&fg=000000&s=0&c=20201002)