
1. Overview of Property Testing
Property testing is a research area in theoretical computer science that has seen a lot of activity over the past 15 years or so. A one-sentence description of this area’s goal is: design algorithms that, given a very large object, examine the object in very few places and decide whether it either has a certain property, or is “far” from having that property.
As a simple example, let the object be the set of all people in Canada, and let the property be “does a majority like Stephen Harper?”. The first algorithm that comes to mind for this problem is: sample a few people at random, ask them if they like Stephen Harper, then return the majority vote of the sample.
Does this algorithm have a good probability of deciding whether a majority of people likes Stephen Harper? The answer is no. Suppose there are 999,999 people in Canada. The sampling algorithm cannot reliably distinguish between the case that exactly 500,000 people like Stephen Harper (a majority) and exactly 499,999 people like Stephen Harper (not a majority).
But our algorithm is in fact a good property testing algorithm for this problem! The reason is that we have not yet discussed the important word “far”. That word allows us to ignore these scenarios that are right “on the boundary” of having the desired property.
In our example, we could formalize the word “far” as meaning “more than 5% of the population needs to change their vote in order for a majority to like Stephen Harper”. Equivalently, our algorithm only needs to distinguish two scenarios:
- At least 500,000 people like Stephen Harper, or
- Less than 450,000 people like Stephen Harper.
Our sampling algorithm has good probability of distinguishing these scenarios. The number of samples needed depends only on the fraction 5% and the desired probability of success, and does not depend on the size of the population. (This is easy to prove using Chernoff bounds.)
This example probably doesn’t excite you very much because statisticians have studied these sorts of polling problems for centuries, and we know all about confidence intervals, etc. The field of property testing does not focus on these simple polling problems, but instead tends to look at problems of a more algebraic or combinatorial flavour. Some central problems in property testing are:
- Given a function
, decide if it is either a linear function or far from a linear function. There is a property testing algorithm for this problem that uses only a constant number of queries. This algorithm is a key ingredient in proving the infamous PCP theorem.
- Given a graph
, decide if
has no triangles, or is far from having no triangles. There is a property testing algorithm for this problem that uses only a constant number of queries, however the constant is a horrifying tower function (a.k.a., a tetration).
2. Testing Sortedness
Let 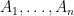


.
- The longest sorted subsequence has length less than
.
We will give a randomized algorithm which can distinguish these cases with constant probability by examining only 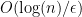
A natural algorithm to try is: pick 


We need to remove at least half of the list to make it sorted. But that algorithm will only find an unsorted pair if it picks 
So instead we consider the following more sophisticated algorithm.
- For
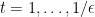
- Pick
uniformly at random.
- Search for the value
in the list using binary search.
- If we discover some unsorted elements during the binary search, return “No”.
- If the binary search does not end up at position
- Return “Yes”.
Theorem 1 This algorithm has constant probability of correctly distinguishing between lists that are sorted and those that are far from sorted.
Proof: If the given list is sorted, obviously every binary search will work correctly and the algorithm will return “Yes”.
So let us suppose that the list is far from sorted. Say that an index
correctly terminates at position
with
. Let
be the last common index of their binary search paths. Then we must have
, which implies that
by distinctness.
Since the list is far from sorted, there can be at most
.
3. Estimating Maximal Matching Size
Our next example deviates from the property testing model described above. Instead of testing whether an object has a property or not, we will estimate some real-valued statistic of that object.
Our example is estimating the size of a maximal matching in a bounded-degree graph. There is an important distinction here. A maximum matching is a matching in the graph such that no other matching contains more edges. A maximal matching is a matching for which it is impossible to get a bigger matching by adding a single edge. Whereas all maximum matchings have the same size, it is not necessarily true that all maximal matchings have the same size.
Here is a greedy algorithm for generating a maximal matching in a graph
,
and maximum degree
.
- Let
.
- Let
be an arbitrary bijection.
- For
- If both endpoints of edge
are uncovered, add
.
Theorem 3 Let
in time
.
Estimating given an oracle. Suppose we have a oracle which, assuming some fixed maximal matching
is covered by that matching
.
The algorithm just involves simple sampling.
- Fix a maximal matching
- Set
.
- For
- Pick a random edge
- Let
if
.
Let
and
. The actual number of edges in
Our estimate for the size of
. Since
, Fact 2 shows that
, which implies that
. Therefore
by a Chernoff bound.
Implementing the oracle. We will not actually implement the oracle for an arbitrary
.
Associate independent random numbers
with each edge
. They are all distinct with probability
, and so they induce a uniformly random ordering on the edges. We let
Our algorithm for implementing the oracle is as follows.
- Given an edge
- For every edge
sharing an endpoint with
- If
, recursively test if
is in the matching. If so, return “No”.
- Let
- Return “Yes”.Clearly this algorithm is always correct: its logic for deciding whether
is equivalent to the greedy algorithm. The only question is: what is the running time of the oracle?
Consider an edge
reachable by a path of length
values in decreasing order. The probability of that event is
. The number of edges reachable by a path of length
. So the expected number of nodes explored is less than
. So the expected time required by an oracle call is
.
Since the estimation algorithm calls the oracle
times, the expected total running time is

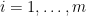
 .
. 
![\displaystyle |M| ~=~ {\mathrm E}[X_i] m ~=~ {\textstyle \frac{m}{k} \mu}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7CM%7C+%7E%3D%7E+%7B%5Cmathrm+E%7D%5BX_i%5D+m+%7E%3D%7E+%7B%5Ctextstyle+%5Cfrac%7Bm%7D%7Bk%7D+%5Cmu%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{array}{rcl} {\textstyle {\mathrm{Pr}}\Big[~ (1-\epsilon) \frac{m}{k} \mu \leq \frac{m}{k} X \leq (1+\epsilon) \frac{m}{k} \mu ~\Big] } &=& {\mathrm{Pr}}\Big[~ (1-\epsilon) \mu \leq X \leq (1+\epsilon) \mu ~\Big] \\ &\geq& 1-2\exp(-\epsilon^2 \mu / 3) ~\geq~ 0.9, \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%7B%5Ctextstyle+%7B%5Cmathrm%7BPr%7D%7D%5CBig%5B%7E+%281-%5Cepsilon%29+%5Cfrac%7Bm%7D%7Bk%7D+%5Cmu+%5Cleq+%5Cfrac%7Bm%7D%7Bk%7D+X+%5Cleq+%281%2B%5Cepsilon%29+%5Cfrac%7Bm%7D%7Bk%7D+%5Cmu+%7E%5CBig%5D+%7D+%26%3D%26+%7B%5Cmathrm%7BPr%7D%7D%5CBig%5B%7E+%281-%5Cepsilon%29+%5Cmu+%5Cleq+X+%5Cleq+%281%2B%5Cepsilon%29+%5Cmu+%7E%5CBig%5D+%5C%5C+%26%5Cgeq%26+1-2%5Cexp%28-%5Cepsilon%5E2+%5Cmu+%2F+3%29+%7E%5Cgeq%7E+0.9%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
